jitsi性能测试结果
本文共 283 字,大约阅读时间需要 1 分钟。
环境: 基于官网搭建的jitsi,包括jitsi-videobridge、jicofo、nginx、tigase(原版是prosody,这里替换成了tigase)。服务器是8核32G。
测试一:
多个客户端进入同一个房间。每个客户端既向上发送数据,也向下接收数据,接收数据时会接收多条流。

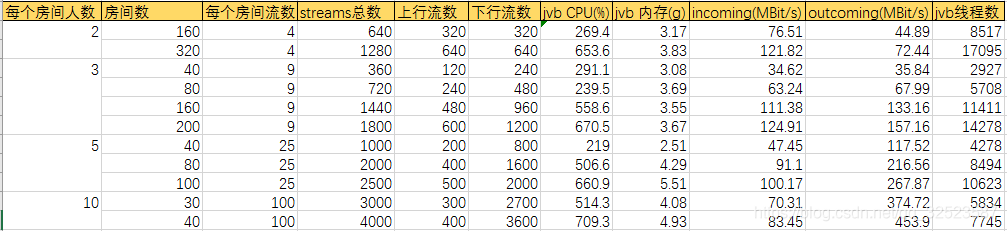
测试二:
客户端进入不同的房间。每个客户端既向上发送数据,也向下接收数据,接收数据时会接收多条流。
测试三:
客户端进入不同的房间。每个客户端仅发送数据,或者接收数据,发送或者接收时只有一条流。
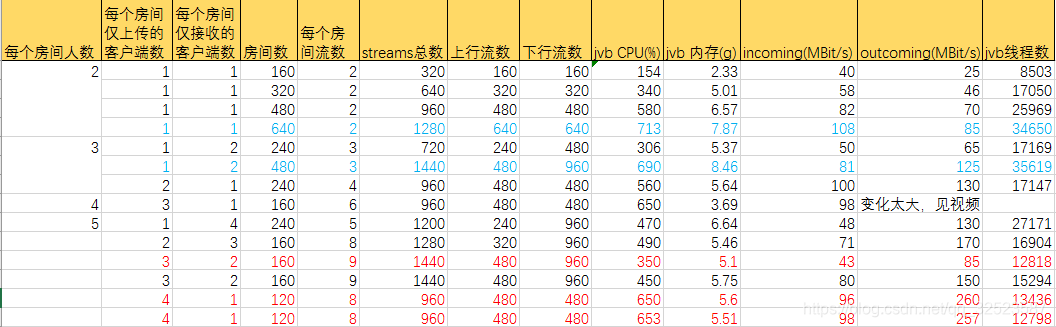
之前jitsi官网上有给出过一个测试的数据, 经对比发现,测试结果差距不是很大。
转载地址:http://avex.baihongyu.com/
你可能感兴趣的文章